
秋季學期的第三門課是 Data Management,談的是 SQL 語言和 Relational Database。這是我比較沒準備也沒概念的一門課,但學了以後才漸漸發覺 Database 是落實 BA Solution 不可或缺的觀念。
秋季學期的安排
終於能在冬季學期結束前,把秋季學期的三門課都介紹完了⋯⋯
- Advanced Econometrics I(理論、分析)
- Computational Methods(實作)
- Data Management(資料庫操作、管理)
這次談的 Data Management 和 Computational Methods 類似,都是讀者如果自學的話比較可能漏掉的領域,因為一般學習過程中不太會碰到需要用 SQL Query 讀取資料的場合,更很少注意到 Relational Database 這個概念。如果是自我練習的話,通常只是讀取 .csv、用個 subset() 或 dplyr 一類的 package 就能處理好資料。
但在實務上,一間企業或一個專案所有的資訊,並不只有一個 .csv 那麼簡單:資訊通常四散各個部門,而且總量可能有數 TB 甚至 PB 這麼高(例如,Boeing 787 光單程就能產生 0.5 TB 的資料),這時除了核心的分析能力,研究人員還得具備有效率地查詢、整合、分析資料的能力,這就是 SQL 和 Database 概念重要的原因。
所以某種程度上,讀者可以把 SQL 當成一門 subset() 的藝術,了解如何最有效率地處理資料,與設計相應的工作流程。等了解了 SQL、Database 概念以及為何它們很重要以後,就能理解 GFS、 HDFS、 MapReduce、 Hadoop、 Spark、 Neo4j 等一連串的應用為何能在這個 Info Explosion 的年代應運而生了。
這讓我想到六個月前剛學 Tableau 時,我也還不了解功能表裡那些資料庫選項的用途。現在我比較清楚了,也能把資料查詢和處理當成單獨、重要的步驟看待。另一方面,對剛步入數位化的中小企業來說,資料庫管理是比資料分析還要基本而且重要的需求,所以學學怎麼設計 Relational Database 也很重要。總之,雖然課名是 Data Management,但要管理虛無飄渺的資訊,就需要設計資料庫和管理流程。以下介紹這門課的主要內容。
老師和教學方法
這門課的老師是 Dr. Floyd,專業是 Information System,過去曾當過很長一段時間顧問,去過比自己年齡數還多的國家。上課給人的感覺很輕快(部分原因是課程本身也不太難)。教學方法比較接近 Tableau,是在有電腦的 Lab 邊上邊操作 Oracle SQL。
用的教科書是 Hoffer 的 Modern Database Management 12th,應該是這個領域最有名,寫得也最詳細的教科書了。它每個章節都整理了很多 Database 相關的觀念,這些觀念一直到我們現在學的 Data Mining 都很受用。唯一的小缺點是整本書真的太厚,講解也有點太細,如果搭配 Teaching Slides 讀起來會有效率一點。
除了 Modern Database Management 中提到的觀念,我們還學了 SQL。說到這個,這是一門少數我可以直接分享教學資源的課程,因為這個神秘的西文網站已經包含了所有 Oracle SQL 的上課講義,外加 Oracle 免費提供的 Oracle Application Express,要靠這些資源自學起初階的 SQL 應該沒問題(也就是說夠考一張 Oracle Database 11g: SQL Fundamentals I 證照了)。
這兩份教材的上課節奏大致上是一段理論,一段實作:先了解什麼是資料庫以後,就學一段 SQL Query,試著查詢資料庫,然後再去讀 Relational Database,最後回去 SQL 介面打造自己的 Database。除了 SQL 以外,我們也學了一點 Microsoft Access,熟悉前端和資料庫概念,畢竟只有 SQL Query 有點抽象,Access(或 Visio)可以用來畫簡單的 ER Diagram,但這不是很必要而且學完就差不多忘了。不過到後面才比較清楚,一個好的 Database System 其實也應該有好的前端,比方說擋下隨便輸入的手機號碼、六月三十一日等錯誤,才能維持資料品質。這些內容有時很難單靠後端的設計,從前端著手反而更方便,也更好維護。Access 方面沒有教材,靠 Dr.Floyd Live Demo 而已。
整堂課的學習目標很單純:學會怎麼用 SQL Query 查詢和建立資料庫,並了解 Relational Database 概念,以及能用 ER Diagram 等工具表達、設計 Relational Database。最後有個 Class Project,是為一間租車公司設計資料庫系統,架構如圖。
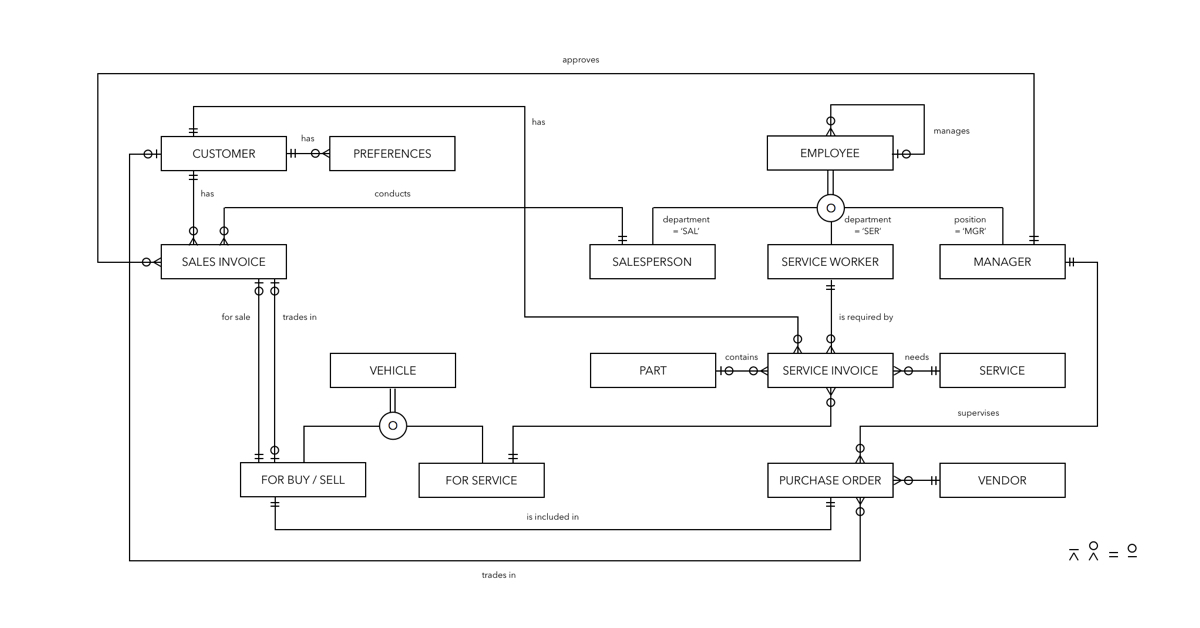
因為我到最後還是不太習慣用 Microsoft Visio 或其他線上 ERD Tools,所以這張是用 Pages 畫的,右下角是紀念用的標誌,分別代表 Mandatory Multiple、Optional Multiple、Mandatory Single 跟 Optional Single,用來表達資料庫中各項紀錄的對應情況。以下整理一下我在這門課學到的東西。
Database Management System
要了解資料庫,我覺得除了想像「海量」以外,最重要的應該是「分散」這個特徵。前者雖然是許多人對企業級資料庫的想像:很多黑色主機排排站、儲存著數以 PB 計的資料等等,但這比較像一種硬性限制:因為資料實在太多了,所以任何動作所耗費的成本都很明顯。
和資料庫觀念比較一脈相承的,應該是分散這件事:讀者可以想像自己的手機,可能大小只有 64 或 128 GB,算不上非常大,但是各個 App、Sensor、Service 所累積的資料散布各個角落。這時,如果讀者想了解「我昨天走了幾步」,可以打開 Health App 查閱步數就好,這就像載入單一 .csv 檔案;但如果讀者想了解的是「我昨天浪費了多少時間」、「我昨天花多少時間在社交上」等比較廣泛的問題,就涉及搜集資料、加總且避免重複、和分析等步驟了。這時,讀者的手機就是一個紀錄日常生活的 Database Management System,手機裡的資料雖然很離散,其中幾個可能可以構成 Relational Databases,其中的 Instances 當然就是被記錄到的日常細節了。
這時讀者可以想像,雖然讀取這些資料可能花不了多少時間,前面提到「海量」這項硬性限制不會影響工作效率,但更讓人頭大的是「我想要的資料在哪裡」、「怎麼有效率地查詢這些資料」等等,這也是整個 DBMS 最關心的核心問題。前面提到的 Modern Database Management,前幾章都是在講類似的概念,只不過對象從手機變成企業的資料庫系統,要解決的問題不是「為什麼最近都不睡覺一直讀李淼帶你看日本」,而是為企業建立一套規範、符合 Business Process 的系統(這當然比一般手機還專門),並藉此解決特定問題。
相關術語
幾個基礎術語和定義如下,怕表達得不精準我就不翻譯了:
| Term | Definition |
|---|---|
| Database Management System (DBMS) | A software system that is used to create, maintain, and provide controlled access to user databases. |
| database | An organized collection of logically related data. |
| relational database | A database that represents data as a collection of tables in which all data relationships are represented by common values in related tables. |
| entity | A person, a place, an object, an event, or a concept in the user environment about which the organization wishes to maintain data. |
| attribute | A property or characteristic of an entity or relationship type that is of interest to the organization. |
| enterprise resource planning (ERP) | A business management system that integrates all functions of the enterprise and provides the data necessary for the enterprise to examine and manage its activities. |
| data independence | The separation of data descriptions from the application programs that use the data. |
用一段話總結上面幾個術語之間的關係:一個 DBMS 負責管理一個或多個 Database,它們可以是分散的幾台主機,例如幾個部門分別記帳、不相往來,也可以是像上面那張拙作,形成 relational database。這些 database 可以包含很多 entity,用來紀錄商業行為中的各種面向,每個 entity 都可以被表達成一張表格,其中的 column/variable 就是 attribute(上圖省略了 attr.)。這類系統的目的之一,是協助企業執行 ERP,清楚了解現況並做出判斷。
設計這套系統的重要觀念之一是 data independence。前面提到 database 可以是分散的幾台主機,但這種情況下可能會發生重複更新、資料分歧等問題,所以學會建立 relationships 並合理利用查詢功能是建立 relational database 的主要原因。

SQL 語言
既然說到查詢或建立資料庫,就得提到 SQL (Structured Query Language)語言,它的功能包括:
- 建立資料庫
- 管理資料格式和內容
- 查詢資料庫
- 計算和衍生(derive)數值
- 建立觸發器(trigger)等程序
所以前面的 subset() 比喻,其實只涵蓋了 SQL 一部分的功能,就算加上 merge() 等函數,也還不包括建立資料庫、寫程序等面向。由於 SQL 在演算法上特別改善了查詢速度(和上一篇提到的讀取速度問題有關),而且上述功能很廣,所以 SQL 已經成為一種常見的標準。不過需要注意的是 SQL 只是一個總稱,發展至今已經隨著各大廠商的不同產品衍生出各種版本。我們學的是 Oracle SQL,和 Microsoft SQL 或 MySQL 就有點差別,但基本上大同小異。
一些例子
一段基本的 SQL Query 長得像這樣:
1 | SELECT last_name, department_id, department_name |
這是從 employees 這個 table/entity 中選取三項 attribute。如果要像 subset() 限制選取對象,可以這樣寫:
1 | SELECT last_name, department_id, department_name, hire_date |
這樣只會選取 2000 年後入職的員工。也可以根據某項 attribute 整合 observations,算出平均值,例如:
1 | SELECT department_id, AVG(salary) |
這樣會返回各部門的平均薪資。讀者讀到這邊可能會覺得「感覺還滿容易的啊」,但還記得前面提到的分散特性嗎?這代表我們得用類似 merge() 的方法將各個 entity 的資料整合在一起。
1 | SELECT last_name, department_id, department_name |
這段 code 將 departments 和 employees 結合再一起,以返回 department_name 這個只存在於 deparements 的 attribute。複雜一點的情況,還可以這樣寫:
1 | SELECT e.last_name, e.job_id, e.department_id, d.department_name |
這裡 JOIN 了兩個 table,並分別用 e、d、l 代稱,節省在 SELECT 的表達,目的是選取在 Toronto 工作的員工的四個 attribute。相信到這裡讀者已經感覺不太對勁了,所以讓我以另一個例子作結:
1 | /* By Joey and Jimmy */ |
我記得這個的題目是「找出買過最多產品顧客的名字」,所以這邊的處理分成三層:
- 找出各
customer_id最高的購買量 - 找出最高購買量所對應的
customer_id - 找出該
customer_id所對應的名字
算上前面兩個 Subqueries 就成了一個看起來很複雜的 SQL Query。SQL 學到精真的也算是一門藝術了。以上寫法神秘西文網站都有包含,不過在學之前,我可以先談我自己的心得。
SQL 語言的實用性
相信看了這些複雜的例子以後,很多讀者的反應是
- 「明明才一句話的問題,為什麼會變得那麼複雜?」
- 「真的有必要學這個嗎?」
「了不起。負責」- 「有沒有更新更簡單的寫法?」
老實說這些都是我們剛開始學 Data Management 的心得,有段時間我們都一直覺得 SQL 就是複雜版的 subset() 罷了,但是如今學完一遍以後,我的感想是學 SQL 還是很必要,因為這是掌握資料庫概念最好的方法,而且就算在最新的技術上,SQL 語言也還是標準。
仔細想想,為什麼一句話的問題,會變成三層 Queries?其實這就和一開始提到的手機例子有關:為什麼問個「我昨天浪費了多少時間」需要調閱多個 App 的資料?因為資料的本質只是離散的紀錄,有時單純的排序或加總無法反映出我們想了解的訊息,所以才需要用多個 subqueries 以衍生出所需的訊息。當然,我有時也會覺得比起 R 裡寫得好好的 packages,這樣自己建構各個過程還是很克難,不過這也正是理解資料庫結構最好的方法,順便培養「別把資訊當成理所當然」的態度。設計一套 SQL Query 考驗的就是邏輯思考。
至於更新的技術或更簡單的寫法,據我所知,即便是比較新的 MongoDB 或 Neo4j 上都還是強調與 SQL 概念的相容性。讀者可以參考 MongoDB 的 SQL to MongoDB Mapping Chart 或 Neo4j 的 From SQL to Cypher – A hands-on Guide,看看寫法之間的差異,背後的原理還是差不多。
最後,我相信一定有某些 Business Intelligence 有類似 Query Builder 之類的工具——只要在 GUI 點選資料就能完成一切,而且也並非一定要 Learn the hard way 才能掌握 SQL 和 Database 概念。以上只是我的個人經驗,分享我確實一度覺得 SQL 很古老和囉唆,但最後認同這也是一門處理資料的藝術,而且經過了十週課程,到現在我還很慶幸自己學過 SQL。一部分原因還是因為這在一般的自學課程中並不多見。
實際練習
如果對 SQL 跟 Modern Database Management 有點概念以後,其實就可以試著找個 Database 或 Business Case 玩玩看了。上一次提到的 chinook.db 就是個很好的例子,它包含了一間唱片行的小型音樂資料庫和銷售資料,讀者可以用 RSQLite 這個 R package 對它練習 SQL Query。這邊提供幾個範例:
一開始讀取資料庫:
1 | library(DBI) |
查詢各個顧客的消費總額(注意 SELECT 和 GROUP BY 中 CustomerId 的重複):
1 | result <- dbGetQuery(chinook, "SELECT CustomerId, SUM(Total) |
查詢 Album、Artist 和 Track 裡的資料:
1 | result <- dbGetQuery(chinook, "SELECT Artist.Name AS ArtistName, |
計算每張專輯的總分鐘數:
1 | result <- dbGetQuery(chinook, "SELECT AlbumId, |
大概就是這樣,當然,要複雜也可以變得很複雜,只是這就留給有心的讀者自己挖掘有趣的寫法了。

從資料庫到解決方案
不過在練習的過程中,我想最重要的應該是留意資料庫和商業流程(DB and Business Process)之間的關係:如何設計一套系統,讓企業足以應付日常活動中的各式需求。以 chinook.db 為例,如果讀者點進剛才的連結裡看它的 ER Diagram,可以發現這套系統基本上有兩個功能:銷售系統和音樂資料庫。這也是我們學這門課的最終目的——學會為企業建構和管理資料庫。我們或許不會成為第一線的技術人員,但至少得清楚一套系統的設計是否合理,以及如何因應不同的商業需求。以下介紹一些構思解決方案時會接觸到的概念。
Entity and Relationship
上面這張圖裡,方框是 Entity,線條是 Relationship,加上右下角四種 Symbol,讀者應該能看出這個系統如何記錄 Vintage Auto 的兩大業務:維修和銷售。
其實最好想像 ERD 的方式,就是把每個 Entity 都當成一份表格(.xlsx or .csv),然後把每個線條都想成 JOIN 表格之後一項資料的有無。所以像左上角 CUSTOMER 和 PREFERENCES 就是兩個表格,一張紀錄顧客資料,一張紀錄顧客的偏好,如果單獨來看它們可能長得像這樣:
顧客表格:
| ID | First Name | Last Name |
|---|---|---|
| 01 | Jimmy | Lin |
| 02 | Simon | Lan |
| 03 | Donald | Trump |
偏好表格:
| ID | Color | Make |
|---|---|---|
| 02 | RED | Porsche |
| 03 | Gold | Cadillac |
| 03 | Black | Lincoln |
所以如果將這兩個表格合併,會發現 Color 和 Make 不但有缺,而且 ID 會重複出現,這就是能從一份 ERD 中讀出的資料關係與商業流程。Entity 和 Relationship 的判斷和設計是資料庫概念的基本功,需要練習一段時間才能熟練,我的建議是就當成實際的表格,並思考自己在什麼情況下會怎麼紀錄。
Database Normalization
另一個常見的狀況,是判斷 Entity and Relationship 的設計是否合理,這時可以用 Database Normalization 的標準來檢驗。Normalization 的層級分成三種,可以參考這份 SJSU 的資料(.ppt,112 KB),這邊舉簡單的例子說明:
1NF:將所有資料都記在一起
在上面的「顧客和偏好」例子裡,最後合併成的大表格就可以看做 1NF 的形式,因為有重複也有缺。這時把這個表格拆回原本的樣子,就可能成為一個 2NF 以上的表格。在這些表格中,很明顯會有個能直接對應到各項紀錄的 ID。在上面的例子裡,顧客的 ID 就對應到顧客的姓名等資料,
偏好雖然沒有自己的 ID,但透過顧客 ID 也能找到相應的偏好。
2NF:存在非依賴(dependent)的數值
上面例子中顧客的 ID 是個 Observation 的決定因素:單一 ID 只會對應到一個人和一組偏好。但如果一個 Observation 中包含和 ID 非依賴的數值,這時就得考慮再將這項數值拆開來,像是這個發票的例子:
| InvoiceID | Product ID | Product |
|---|---|---|
| 01 | 01 | MacBook Pro |
| 01 | 02 | Nintendo Switch |
| 01 | 03 | iPhone |
這時我們能看出其實 Product 是依賴在 ProductID 而非 InvoiceID 上的,所以我們可以考慮在發票這個資料庫中保留 InvoiceID 和 ProductID 就好,然後將價格、商品名稱等資料另外獨立成一個資料庫。
3NF:便於更新和查詢的理想狀態
把 Dependency 和 Redundancy 處理好以後,一個分散但彼此支援的資料庫系統就是理想狀態。在這種情況下,資料更新或刪除不會造成其他資訊遺失或分歧等問題。所以如果發票上沒有出現 MacBook Pro 的資料,我們還是能從單獨的資料庫中找到它的 ProductID 等資料;就算 Donald Trump 的偏好從 Gold 改成 Blue,也不會改變 Gold Cadillac 存在的事實。
心法:避免 Anomaly
不論是 ER 的設計還是判讀 Normalization Form,了解設計中的各項假設、測試資料庫、並確定其符合實際需求才能造就好的解決方案。常見的問題包括:
- 更新後資訊遺失或分歧,如 1NF 或 2NF 會有的問題
- 資料型態漏洞,像是可以輸入隨便的手機號碼
- 資料缺失或不一致,像是能在沒有
ID的情況下輸入顧客姓名
有些設計或許應付得了一時的需求,但隨著商業發展可能會不敷使用。不過這時固執選擇最好的解決方案,有時礙於限制也不切實際,所以比較中性的作法應該是將設計時的假設說清楚,像是「姓名不會超過 25 位」、「金額應該都是正數」等等。為資料庫建立明確的 Guideline,才是完整的解決方案。

路是無限寬廣
這門課的內容差不多就這樣,老實說介紹起來感覺有點短,我還特別回想了一下:學 SQL、讀 Modern Database Management、碰一些 Access 還有畫二十幾張 ER Diagram⋯⋯好像差不多就這樣。之所以上起來會感覺很漫長,大概是因為 Entity and Relationship 真的是需要花時間才能掌握的概念,加上 SQL、Access 學起來都有很多細節,以及期末的 Project 真的很花時間(那張拙作連同背後的 .sql 至少花了我三十小時),才會覺得這門課真的有點重(還要加上找工作等外務)。
不過上完以後我對資料庫還是滿感興趣,尤其在最後一節課,Professor Floyd 請了班上兩位以前就學過 SQL 所以免聽的同學來介紹 Neo4j 和 Hadoop,也讓我對資料庫的前沿發展有點認識,像是 Spark 和 Hadoop 的關係、MapReduce 的原理和歷史、以及如今 Apache 底下各項產品和 Neo4j 等新型資料庫的特徵和性能等等。不過我滿確定自己不會往前線開發的方向走,只希望等這些技術標準化以後,自己還懂得怎麼用學過的 SQL 知識設計流程和調閱資料。
最後,這門課最重要的收穫之一,大概是在自己碰了這麼多工具和技術以後,真心認同 Professor Floyd 在課程尾聲說的一句話。他說這個 Program 不會把你們變成 Data Scientist,但你們得學會如何運用這些技術解決商業問題。由於 Data Science 是很廣的領域,與 Stats 和 CS 都有點關聯,所以剛開始學的時候我也是什麼都讀,而且很想往技術高原邁進。因為當時我相信這樣才不會被源源不絕的新進人才和技術給淹沒。
但在探索的過程中,我一方面意識到自己對理論的興趣,大多僅止於了解概念和用法,但不是特別對研究感興趣;一方面我也發現除了技術以外,其實實作也是個值得挑戰的能力。畢竟如果一般中小企業連好的 DBMS 都沒有,了解各種酷演算法又有什麼用呢?所以 Data Management 在這段探索期間,稍稍提醒了我合理的定位,並讓我在做 Project 的過程中驗證這些想法。雖然這門課本身並不難,我一開始也沒什麼準備,中間也常跟同學抱怨 SQL 真是一門麻煩的語言,但到現在我還真感謝 Professor Floyd 帶我們入門這個領域。
經過這門課以後,我也更加確定:我喜歡解決問題,也喜歡應用新方法。Data Science 對我來說很廣,我會選一條走起來適合我(但不至於安逸或無聊)的路。我現在也還在用這學期的 Industry Project 測試自己,不過關於這個的文章可能得等到兩個月後了(在我拿到 Nintendo Switch 之後)。
走走拍拍:Oracle Corporation、Cerro SLO、Cal Poly Kennedy Library、Santa Rosa SLO